
티스토리 뷰
딥러닝이 다양한 분야에 활용되면서 텍스트, 음성, 이미지, 시계열 데이터와 같이 시간적 흐름이나 공간적 패턴을 가진 데이터를 다루는 일이 많아졌습니다. 이러한 데이터를 효과적으로 처리하기 위해 다양한 신경망 구조들이 제안되었고, 각 모델은 목적과 특성에 따라 다양한 분야에서 사용되고 있습니다.
이 글에서는 대표적인 딥러닝 모델인 RNN, LSTM, GRU, CNN, Transformer의 개념과 특징을 간단하게 정리해 보았습니다.
(내용 중 잘못된 부분이 있다면 알려주시면 감사하겠습니다.)
RNN (Recurrent Neural Network)

RNN은 문장이나 음성처럼 순차적인 데이터를 처리하기 위해 고안된 구조입니다.
이전 단계의 출력을 현재 입력과 함께 처리함으로써, 시간에 따라 정보를 누적하고 기억할 수 있습니다.
x₁ → h₁ → y₁
↓
x₂ → h₂ → y₂
↓
x₃ → h₃ → y₃
- x₁, x₂, ... : 시점별 입력 데이터 (예: 단어)
- h₁, h₂, ... : 은닉 상태 (기억 역할)
- y₁, y₂, ... : 출력
RNN 한계점
- 문장이 길어질수록 이전 정보가 희미해지는 현상(gradient vanishing, 기울기 소실 문제) 발생
- 과거의 중요한 단어가 뒤로 갈수록 영향력을 잃음
LSTM (Long Short-Term Memory)
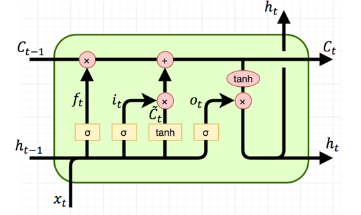
LSTM은 RNN의 단점인 장기 기억 유지 문제를 해결하기 위해 등장한 구조입니다.
중요한 정보를 얼마나 오래 기억할지를 스스로 판단하는 구조를 갖고 있습니다.
LSTM 주요 구성 요소
- Input Gate: 새로 저장할 정보 결정
- Forget Gate: 잊을 정보를 결정
- Output Gate: 최종 출력할 정보 선택
LSTM은 이런 구조를 통해 긴 문맥이 필요한 기계 번역, 대화 모델 등에 널리 사용됩니다.
LSTM 단점
- 구조가 복잡하고, 계산량이 많아 학습 속도가 느림
GRU (Gated Recurrent Unit)
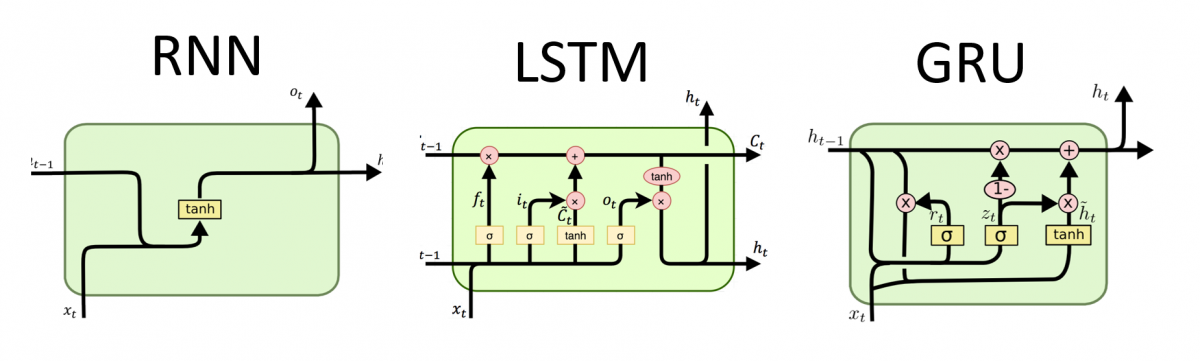
GRU는 LSTM과 유사한 목적을 가지되, 구조를 더 간단하게 만든 모델입니다.
- GRU에는 Update Gate와 Reset Gate 두 개만 있음
- 구조가 단순한 만큼 연산량이 적고 학습 속도 빠름
- 성능은 LSTM과 거의 비슷한 경우도 많음
GRU 주요 구성 요소
- Update Gate: 얼마나 과거를 유지할지 결정
- Reset Gate: 과거 정보를 얼마나 무시할지 결정
GRU 장점
- 연산량이 적고, 학습 속도가 빠름
- LSTM과 유사한 성능을 적은 비용으로 달성 가능
→ 실시간 예측, 모바일 환경 등에서 자주 사용됩니다.
CNN (Convolutional Neural Network)

RNN 계열이 시간 순서를 잘 처리한다면, CNN은 공간 구조가 중요한 데이터, 즉 이미지와 같은 2차원 데이터를 처리하는 데 특화된 모델입니다.
왜 이미지에 적합할까?
이미지는 수많은 픽셀로 이루어진 2차원 데이터입니다.
예를 들어 강아지 사진을 생각해 보면, 귀, 눈, 입 같은 특징들이 서로 일정한 공간적 관계를 가지며 배치되어 있습니다.
이런 특징은 단순히 어떤 픽셀이 어떤 값을 가지는지보다, 어디에 위치하고 있는지, 주변과 어떤 관계를 맺고 있는지가 더 중요합니다.
CNN은 어떻게 다를까?
CNN은 기존의 완전연결 신경망과 달리, 합성곱(Convolution) 연산을 통해 입력 데이터에서 국소적인 패턴(local feature)을 추출합니다.
CNN은 작은 필터를 이용해 이미지를 훑으며, 다음과 같은 특징을 추출합니다.
- 윤곽선(Edge)
- 색상 변화
- 특정 형태
이렇게 추출된 특징들은 점차 추상화되어 “강아지의 귀” → “ 강아지의 얼굴” → “강아지”처럼 더 큰 의미를 갖는 특징으로 발전하게 됩니다.
CNN 주요 구성 요소
- Convolution Layer: 작은 필터를 사용해 이미지에서 특징 추출
- ReLU (Activation Function): 비선형성을 부여해 복잡한 패턴을 학습
- Pooling Layer: 특징을 요약해 계산량을 줄이고 과적합 방지
- Fully Connected Layer: 추출된 특징을 기반으로 최종 분류 수행
CNN은 이미지뿐 아니라, 1D CNN 형태로 시계열 데이터나 문장 처리에도 응용됩니다. (예: 감정 분석, 문장 분류 등)
Transformer
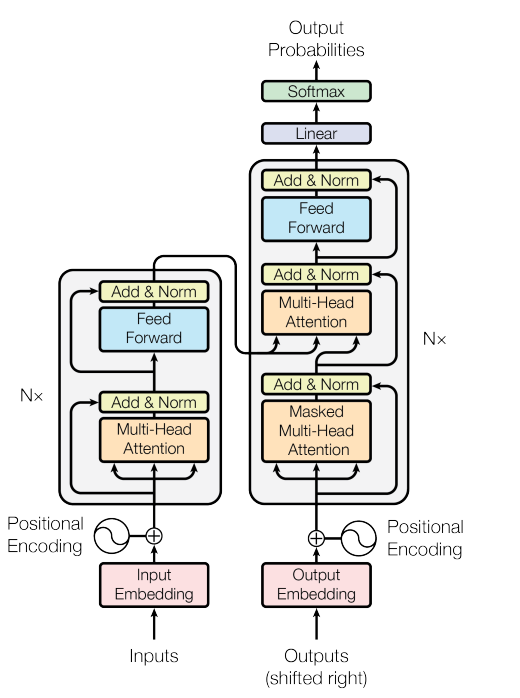
Transformer는 기존 RNN 기반 모델이 가진 순차 처리의 한계를 극복한 모델로, 오늘날 대부분의 대형 언어 모델(GPT, BERT 등)의 기반 구조입니다.
핵심 아이디어: Self-Attention → 모든 단어가 다른 단어들과 얼마나 중요한 관계를 가지는지 스스로 판단하자.
예시 문장: "The animal didn’t cross the street because it was too tired."
예시 문장에서 it(= animal)이 무엇을 의미하는지 이해하려면 전체 문장을 봐야 합니다.
하지만 Self-Attention은 각 단어가 문장 내 다른 모든 단어와의 연관성을 계산해, 전체 문맥을 이해할 수 있게 합니다.
Transformer 주요 구성 요소
- Input Embedding + Positional Encoding: 단어 의미 + 순서 정보를 함께 입력
- Multi-Head Attention: 다양한 관점에서 문맥을 동시에 파악
- Feed-Forward Network: 각 단어 위치별로 정보 독립적으로 처리
- Layer Normalization + Residual Connection: 정규화와 Residual Connection을 통해 안정적인 학습 지원
Transformer 장점
- 병렬 처리 가능 → 학습 속도 빠름
- 문장 길이가 길어도 문맥 이해가 뛰어남
- GPT, BERT, ChatGPT 등 최신 LLM 모두 Transformer 기반
모델 비교 요약
| 모델 | 주요 특징 | 장점 | 단점 | 활용 분야 |
| RNN | 순차적 데이터 처리 | 구조 단순, 시간 흐름 반영 | 장기 의존성 학습 어려움 (기울기 소실) |
텍스트, 음성 |
| LSTM | 장기 의존성 정보 기억 가능 | 긴 문맥 처리 가능, 기울기 소실 완화 |
구조 복잡, 느린 학습 속도 |
기계 번역, 챗봇 |
| GRU | 간소화된 LSTM 구조 | 빠른 학습, 효율적 메모리 사용 | LSTM보다 표현력 다소 낮을 수 있음 |
음성 인식, 시계열 예측 |
| CNN | 지역적 특징 추출 (Convolution) |
병렬 처리 용이, 이미지 처리에 최적화 |
시퀀스·문맥 정보 처리에 부적합 | 이미지 분류, 객체 탐지, 영상 처리 |
| Transformer | Self-Attention 기반, 순서 정보 포함 가능 | 병렬 처리, 장기 의존성 학습에 탁월 |
구조 복잡, 계산량 많음 | 언어 모델, 문서 요약, 번역, 코드 생성 |
마무리
데이터의 형태와 처리 목적에 따라 적절한 딥러닝 모델을 선택하는 것은 매우 중요합니다.
- 시퀀스 중심 데이터 → RNN, LSTM, GRU
- 공간 중심 데이터 → CNN
- 고성능 문맥 이해와 병렬 처리 → Transformer
요즘은 이 구조들을 조합하거나 변형하여 모델을 만드는 경우도 많습니다.
[예시] 유튜브 링크
참고
- Total
- Today
- Yesterday
- relative to center
- gpu rte
- geodetic
- b3dm
- parallel operation
- reciprocal approximation
- 3d tiles
- cpu rte
- sw 마에스트로 15기
- 3d tiles 1.0
- gltf
- netwon-rapshon
- coordinate transformation
- * to gltf
- gpu rte dsfun90
- 3d engine design for virtual globes
- ear cut
- topcit 고득점
- relative to eye
- 좌표 변환
- 삼각분할
- * to glb
- virtual globe
- .b3dm
- 탑싯 고득점
- b3dm to glb
- ear clipping
- high-low encoding
- 병렬 연산
- 역수 근사
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |