목차
- 문제 정의: 분산 시스템과 Dual Write
- 문제 유형 1: 상태 전파 지연 (일시적 불일치)
- 문제 유형 2: 시스템 장애 (정합성 붕괴)
- Case A: 이벤트 유실 (Outbox, CDC)
- Case B: 유령 데이터 (이중 방어 전략: 선제적 검증, 상태 머신 & 자가 치유)
- 결론: 대응 전략 요약
1. 문제 정의: 분산 시스템과 Dual Write
1.1 분산 시스템과 상태 관리
분산 시스템은 하나의 목표를 위해 여러 노드가 네트워크로 협력하는 구조다.
각 노드는 메모리를 공유하지 않으며, 상태 전달은 오직 네트워크 메시지 통신에 의존한다.
많은 서비스는 다음과 같이 여러 이종(Heterogeneous) 시스템에 상태를 분산 저장한다.
- RDBMS: 원본 데이터 영속화 (= Source of Truth)
- Cache (Redis): 고성능 조회를 위한 임시 저장
- Search (Elasticsearch): 검색 및 분석
- Queue (Kafka): 타 도메인 이벤트 전파
- 외부 API: PG 결제 요청, 지도 길 찾기, 공공 API 등
즉, 클라이언트의 하나의 요청(Request)은 내부적으로 여러 시스템의 상태 변경을 유발한다.
1.2 Dual Write란?
Dual Write는 "두 개 이상의 서로 다른 시스템에 데이터를 변경하는 행위가 단일 트랜잭션(Atomicity)으로 보장되지 않는 상황"을 말한다.

@Transactional
public void updateNickname(Long userId, String nickname) {
userRepository.updateNickname(userId, nickname); // 1. DB 반영 (트랜잭션 관리)
// --- 물리적 분리선 (네트워크 구간) ---
redisCache.evict(userId); // 2. Redis 반영 (네트워크 호출)
}위 코드는 논리적으로 하나의 작업 같지만, 물리적으로는 DB 트랜잭션 커밋과 외부 시스템(Redis) 호출이 분리되어 있다.
이 사이에는 네트워크 지연이나 장애가 개입할 틈이 존재하며, 필연적으로 데이터 불일치가 발생한다.
1.3 데이터 불일치가 발생하는 이유

분산 환경에서 한 시스템의 변경이 다른 시스템에 "즉시, 그리고 반드시" 반영됨을 보장할 수 없는 이유는 다음과 같다.
- 네트워크의 불확실성: 네트워크는 언제든 지연(Latency)되거나 단절(Partition)될 수 있다.
- 부분 실패 (Partial Failure): DB는 성공했으나 Redis는 타임아웃으로 실패할 수 있다. 전체가 성공하거나 전체가 실패하는 원자성(Atomicity)이 깨진다.
- 분산 트랜잭션의 부재: 성능상의 이유로 RDBMS와 NoSQL/Messaging Queue 간에 2PC(2 Phase Commit) 같은 강한 트랜잭션을 사용하지 않는다.
이로 인해 발생하는 문제는 크게 두 가지 성격으로 나뉜다.
- 네트워크 지연으로 전파가 늦어지는 "일시적 불일치 (Eventual Inconsistency)"
- 장애로 인해 상태가 영구적으로 어긋나는 "정합성 붕괴 (Data Integrity Violation)"
2. 문제 유형 1: 상태 전파 지연 (일시적 불일치)
시스템이 정상적으로 동작하더라도, 네트워크 지연으로 인해 DB에는 반영되었으나 외부 시스템(캐시/검색)에는 아직 도달하지 못한 시간차가 발생한다.
2.1 현상: 읽기 불일치 (Read Inconsistency)

- 상황: 사용자가 닉네임을 변경하고 즉시 프로필을 조회한다.
- 전개: DB 업데이트는 성공했으나, 캐시 갱신(Evict/Set)이 네트워크 지연으로 대기 중이다.
- 결과: 사용자는 Redis를 조회하고, 변경 전의 과거 데이터를 보게 된다.
2.2 대응 전략: 일관성 규칙 정하기
이것은 버그가 아니라 분산 시스템의 특징이다. 따라서 무조건 막는 것이 아니라 비즈니스 중요도에 따라 결정한다.
- 허용 (Eventual Consistency, 결과적 일관성) : SNS 좋아요, 조회수 등은 일시적으로 불일치해도 치명적이지 않다. 시간이 지나면 수렴하므로, 이는 정합성 문제라기보다 UX의 문제로 접근한다.
- 통제 (Strong Consistency, 강한 일관성): 결제 결과, 재고 등 민감한 데이터는 캐시를 우회하고 DB(Source of Truth)를 직접 조회하거나, 클라이언트 레벨에서 낙관적 UI 업데이트를 수행한다.
- 참고: DB 복제 지연 (Replication Lag) DB의 Master → Slave 복제 또한 네트워크를 타므로 지연이 발생한다. Write 직후 Slave에서 읽으면 데이터 불일치가 발생할 수 있다. 민감한 데이터는 Master에서 읽는 전략이 필요하다.
3. 문제 유형 2: 시스템 장애 (정합성 붕괴)
지연이 아니라 프로세스 크래시(Crash)나 통신 장애가 개입되면 문제는 심각해진다.
한쪽만 성공하고 다른 쪽은 실패하여, 상태가 영구적으로 불일치하는 비수렴(Non-convergence) 상태가 된다.
3.1 Case A: 내부 성공, 외부 전파 실패 (이벤트 유실)

Source of Truth(DB)는 업데이트되었으나, 후속 처리를 위한 이벤트 발행이나 외부 호출이 실패한 경우다.
- 상황: 결제 승인(DB) 후 Kafka 이벤트 발행 시도 중 서버 다운.
- 결과: 결제 후, 주문 내역은 생겼는데, 알림 미발송, 정산 누락 등 후속 로직이 실종된다.
[해결책 1] Transactional Outbox 패턴
비즈니스 데이터와 "발행할 이벤트"를 동일한 DB 트랜잭션 내의 Outbox 테이블에 저장한다. 이후 별도의 Polling 프로세스가 이를 읽어 발행한다.
- 장점: At-least-once(최소 1회) 전송을 보장하는 가장 확실한 방법
- 단점: 별도의 Outbox 테이블과 폴링/릴레이 구조를 구현해야 한다.
[해결책 2] CDC (Change Data Capture)
애플리케이션은 DB 커밋만 하고, 인프라 레벨(Kafka Connect, Debezium)에서 DB 트랜잭션 로그(WAL/Binlog)를 읽어 이벤트를 발행한다.
- 장점: 애플리케이션 코드 결합도가 0에 수렴한다. 성능 오버헤드가 적다.
- 단점: 운영 복잡도가 높고, 인프라 구축 비용이 든다.
3.2 Case B: 외부 성공, 내부 실패 (유령 데이터)
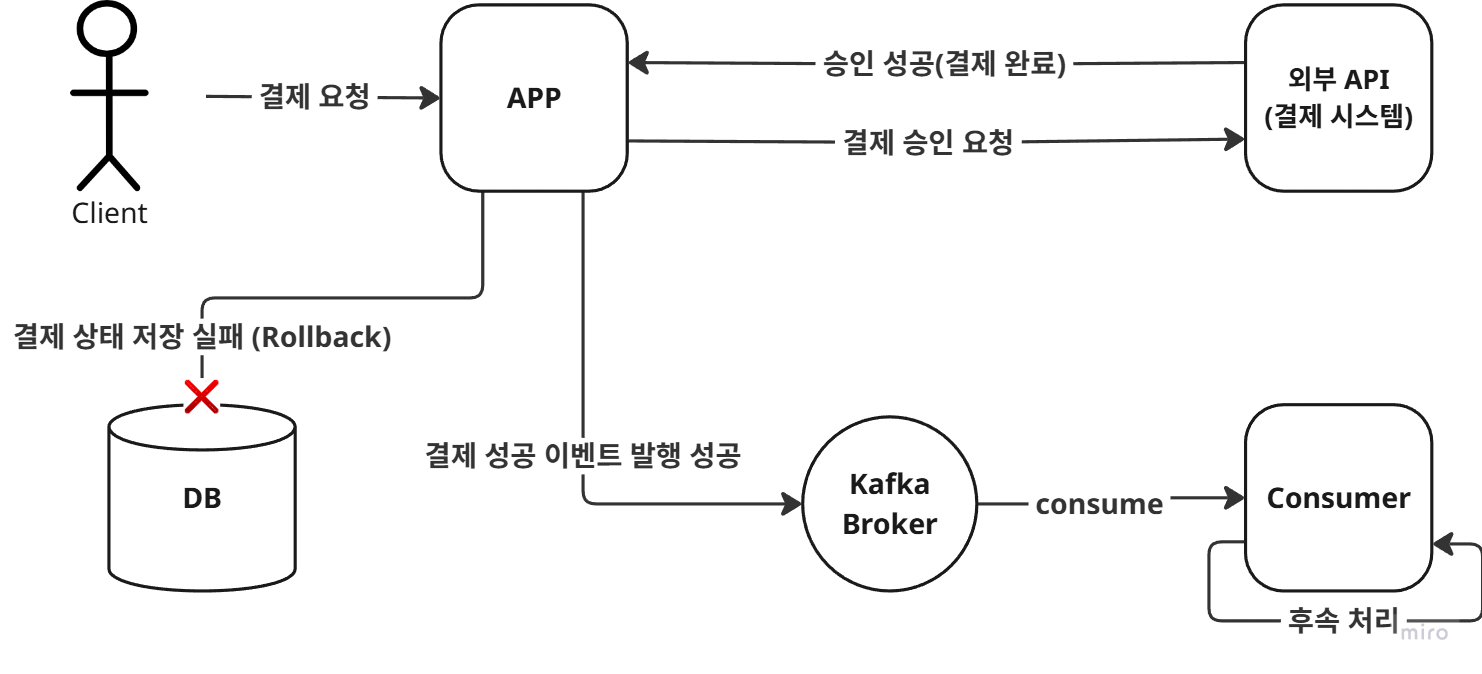
외부 시스템(결제 시스템, 타 마이크로서비스 등) 호출은 성공했으나, 내부 DB 반영(트랜잭션 커밋)에 실패한 경우다
- 상황: 외부 결제 시스템 결제 승인 성공 → 내부 DB ORDER 테이블 Insert 중 에러(Rollback)
- 결과: 결제는 됐는데 주문 내역이 없는 유령 데이터(Phantom Record)가 발생한다.
- 영향: 사용자가 재시도하면 중복 결제가 발생한다. 가장 치명적인 정합성 붕괴 상황이다.
실무에서는 이 문제를 완벽하게 방어하기 위해 실시간 복구(1번)와 비동기 복구(2번)를 결합하여 상호 보완적인 이중 방어선을 구축한다.
[전제 조건] 트랜잭션 분리와 상태 체크포인트 (State Checkpoint)
Case B를 해결하기 위해선 트랜잭션을 분리하여 실패 시점 이전에 의도를 기록해야 한다.
- Tx 1 (Checkpoint): PENDING 상태 기록 (커밋)
- 외부 시스템 호출
- Tx 2 (Update): 결과(SUCCESS/FAIL) 갱신 (커밋)
이 전제 조건을 바탕으로 동기와 비동기 방식을 결합한 복구 모델을 구축하여 정합성을 보장한다.
[해결책 1] 동기적 복구 (Synchronous Read Repair)
사용자가 오류를 인지하고 "재시도(Retry)" 버튼을 누르는 시점에 즉시 복구하는 전략이다.
- 원리: 멱등성(Idempotency) 키를 활용한 읽기 복구(Read Repair)
- 구현:
- 클라이언트가 동일한 orderId로 재결제를 요청한다.
- 서버는 로직 실행 전, 외부 시스템(PG)에 해당 orderId의 결제 내역을 조회(Verification)한다.
- 이미 승인된 건이라면: 내부 DB에 주문을 강제로 생성하거나 상태를 업데이트하여 정상 처리 결과를 반환한다.
- 승인된 건이 없다면: 정상적인 결제 로직을 진행한다.
- 장점: 사용자 관점에서 가장 빠르게 문제가 해결된다.
- 한계: 사용자가 재시도를 하지 않고 이탈하면 복구할 수 없다.
[해결책 2] 비동기 배치
사용자가 재시도를 하지 않고 이탈해버린 경우를 구제하기 위해, 시스템이 스스로 복구하는 전략이다. (해결책 1을 보완하는 역할을 한다.)
핵심은 "의도를 먼저 기록(Checkpoint)"하는 것이다.
- 원리: 오래된 PENDING 상태 데이터를 찾아 외부 상태와 대조(Reconciliation)
- 구현:
- 배치(Batch) 프로그램이 주기적으로 실행된다. (예: 1분 간격)
- DB에서 PENDING 상태로 N분 이상 머물러 있는 "고아 데이터"를 조회한다.
- 해당 건들에 대해 외부 시스템(PG) 상태 조회 API를 호출한다.
- 외부 시스템이 성공 상태라면 → 내부 DB를 SUCCESS로 업데이트 (자가 치유)
- 외부 시스템에 내역이 없다면 → 내부 DB를 FAIL 처리 (자원 해제)
- 장점: 사용자 개입 없이 시스템이 최종적 일관성(Eventual Consistency)을 보장한다.
- 한계: 배치가 실행되기 전까지 데이터 불일치 구간이 존재한다.
[결론] 상호 보완 구조의 필요성
- 동기적 복구로 사용자의 즉각적인 불편(재시도 시 중복 결제 방지)을 해소하고,
- 비동기 배치로 놓친 데이터를 최종적으로 수거하여 정합성을 보장해야 한다.
⚠️ 근데 여기서 치명적인 문제가 있다.
"사용자가 결제는 성공했는데 주문에 실패했다. 이를 내부 시스템이 1분 뒤에 배치를 돌려 확인하고 환불한다."
기술적으로는 정합성이 맞지만, 비즈니스 관점에서는 1분 동안 사용자가 '내 돈 먹튀 당했나?'라며 불안에 떨어야 한다.
- 배치 기반 자가 치유는 시스템의 오염을 막는 '최후의 안전장치'일 뿐, 완벽한 UX를 보장하지 못한다.
- 만약 사용자가 결제 실패 직후 즉시 환불 결과를 봐야 한다면, 단순한 사후 복구를 넘는 '동기화된 롤백'이 필요하다.
이러한 실시간성이 비즈니스에 필수적이라면 분산 트랜잭션을 도입해야 한다.
4. 결론: 대응 전략 요약
Dual Write 환경에서는 "전파 지연"과 "장애 발생"문제를 명확히 구분하여 대응해야 한다.
| 구분 | 세부 유형 | 현상 | 수렴 여부 | 핵심 대응 전략 |
| 전파 지연 | 일시적 불일치 | DB엔 있는데 캐시엔 없음 | O (시간 지나면 해결) |
- 캐시 TTL 전략 - 비즈니스 허용 (Eventual Consistency) |
| 시스템 장애 | Case A: 이벤트 유실 |
[내부 성공 → 외부 실패] 결제 O, 주문 O, 알림 X |
X (영구 유실) |
- Transactional Outbox - CDC (Change Data Capture) |
| 시스템 장애 | Case B: 유령 데이터 |
[외부 성공 → 내부 실패] 결제 O, 주문 X |
X (영구 불일치) |
- 선제적 검증 (재시도 시) - 자가 치유 (Batch Cross-check) - 멱등성(Idempotency) 보장 |
기술 도입 가이드
Q1. "잠깐 데이터가 달라도 되는가?" (단순 조회)
- Yes: [전파 지연]으로 간주하고 허용 (Eventual Consistency)
- 예시: SNS 좋아요 수, 조회수, 게시글 목록 갱신
Q2. "장애 발생 시, 사용자가 나중에 결과를 받아도 되는가?" (알림/적립)
- Yes: [Outbox 패턴 / CDC]과 [자가 치유 배치]로 해결
- 이유: 비동기 복구로도 비즈니스 목표를 달성할 수 있다.
- 예시: 알림 발송, 포인트 적립, 통계 데이터 집계
Q3. "장애 발생 즉시, 실패를 알리고 롤백해야 하는가?" (돈/재고)
- Yes: 배치의 지연 시간(Latency)을 허용할 수 없다. 즉시 롤백을 위해 [분산 트랜잭션] 도입이 필수적이다.
- 이유: 사용자는 돈이 나갔는데 주문이 안 된 상황을 단 1초도 견디기 힘들어한다.
- 예시: 결제 차감, 재고 선점, 티켓팅
Next Step
이번 글에서는 "데이터 동기화와 자가 치유(Self-Healing)" 관점에서 데이터 정합성을 확보하는 방법을 알아봤다.
하지만 결론에서 언급했듯, "1분의 지연도 허용할 수 없는 즉각적인 롤백"이 필요한 상황이라면 어떻게 해야 할까?
단순한 재시도나 사후 보정만으로는 해결되지 않는 비즈니스적 원자성이 필요할 때가 있다.
다음 포스팅에서는 외부 API가 2개 이상 껴있는 상황에서 즉시 롤백을 보장하는 분산 트랜잭션 기법, Saga 패턴과 TCC(Try-Confirm-Cancel), 그리고 전통적인 2PC(Two-Phase Commit)의 개념과 실무 적용 전략에 대해 다룰 예정이다.
'분산 시스템' 카테고리의 다른 글
| 분산 시스템 시간 정합성: UTC, NTP, 그리고 관용 (0) | 2025.12.23 |
|---|---|
| CAP, PACELC 개념·트레이드오프 정리 (5) | 2025.08.21 |

